
New functionality without bugs – a case of billing for a mobile operator
Zero errors upon completion of integration tests – that’s about testing new functionality at business acceptance on the operator's side. A few words about how this testing works.
We release new versions of our billing software on schedule, 6 times a year. Release shipping dates are known in advance. As I’m writing this article, we already have planned release dates for the entire next year.
That’s because of the race of mobile operators for time-to-market. The core principle is that the subscriber should regularly receive new billing features. Payments from smartphone, keeping your number when changing the operator, the ability to sell unused data – updates may be different.
We might be unaware of what exactly we will release in a year, but we know for sure when the update is to be released. It helps us to keep the pace.
There are about 70 people working at a release. That is 5-6 teams, each specializing in some area: analytics, development (several teams), functional testing, integration testing.
Yes, we use Waterfall approach in billing projects. But this story is not about how we radically switched the development paradigm from waterfall to Agile or vice versa. Each development approach has its advantages and is good in the right conditions; I want to leave this discussion outside the scope of this article. Today I want to talk about evolutionary development: how we moved to zero errors at the acceptance of release within the framework of the existing approach to development.
The discomfort zone
At the beginning of the story, two years ago, we had the following picture:
- at the end of the development chain the teams would be overwhelmed;
- "it's time to pass it to the next stage team, but the previous team has just begun its part of the work";
- after our cycles of testing the customer would find up to 70 errors.
Errors that were found as the results of integration tests could be minor ("part of the message is displayed as dashes") or critical ("transition to another billing plan fails").

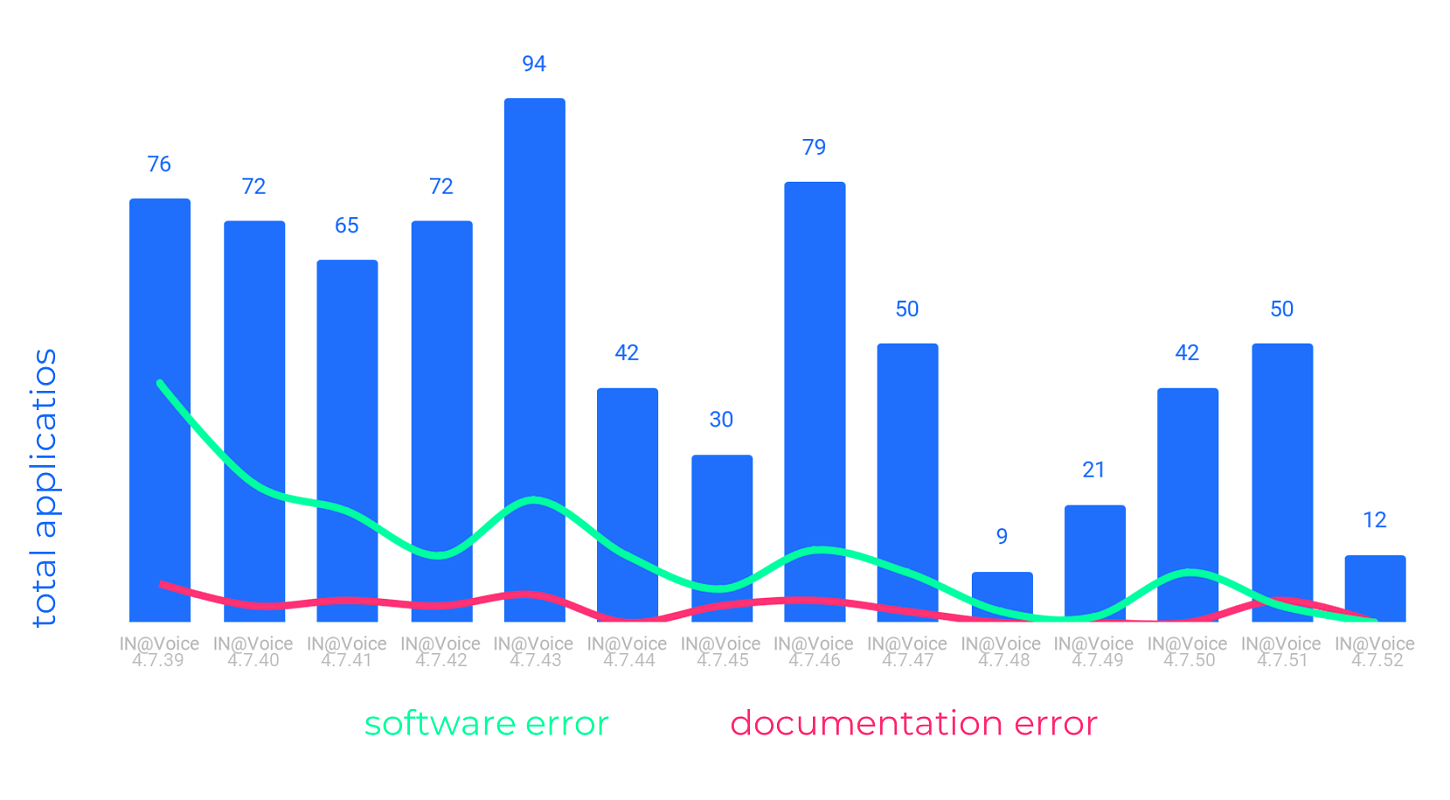
A year later, we managed to reduce the number of errors to 10-15, by mid-2020 – to 2-3. And in September, we succeeded in achieving the target zero errors.
We managed due to improvements in several areas: tools, expertise, documentation, work with the customer, and last, but not least, the team. Improvements varied in cruciality: to know the specifics and processes of the customer is important; to switch to a new scale for assessing the complexity of tasks is nice to have; and to work with the team’s motivation is of utmost importance. But first things first.
Growth areas
The main tool of integration testing is a testbed. There we emulate the subscriber's activity.
General testbeds
Dumps from production are loaded and deployed at the testbeds to make the conditions as realistic as possible.
The catch is that the dumps on our testbeds and those of the customer's could be different. The operator makes a dump, passes it to us, we test new functionality, catch and fix bugs. We give the finished functionality to the customer, and colleagues on the other side begin testing. Our dumps could differ: for instance, we tested that of July, the operator – the August dump.
The differences are not critical, but there were still differences. It resulted in errors occurring on the customer's side, that hadn’t occurred on ours.
To address it we agreed that the data schemes on which the testing takes place will be the same, and in general we will have a common testbed.
The lagging of dumps remained, but we minimized it setting up the infrastructure. Thus reducing the number of errors caused by differences between test and production environments.
Validate settings before testing
When we ship a new version of the software to the operator, we need to make settings for testing at the customer’s side, that is not only about customizing the new functionality, but perhaps to additionally customize the old one.
We wrote documentation about the required settings. But information in the manuals could be distorted. The documentation is written by some people, and read by other people, and sometimes misunderstandings occur.
It’s particular about our software: the settings are subject to high requirements for flexibility and readiness. The settings are complicated, and documentation alone was not always able to convey all the necessary information without additional communication.
As a result, the settings were not always correct, and it led to errors detection during testing on the operator's side. We analyzed it and found out that the errors were not of the software, but of the settings. We couldn’t afford to waste precious time on such errors.
What we did was to introduce a procedure for checking our settings on the customer's side before starting testing on the operator's stands.
The process became as follows: the customer chooses the cases that we show on the customized testbed. We run the tests. If there are errors, we promptly correct them; if not, the test is considered passed.
Additional communication relating to the documentation
Aligning on the settings before testing on top of the settings description provided in the manuals, is just one example of additional communication related to the documentation. But there were others.
For example, we ensured that there’s always an specialist available for our customers to contact at any time regarding the documentation and the system as a whole. Something like a dedicated technical support line with our highly qualified specialists.
Our technical writers organized workshops to train the customer's employees on the use of new functionality.
The process documentation transfer became less discrete and more continuous: now the new information, clarifications, recommendations were sent as they became available or were requested even after the main manuals had been provided.
All this allowed to better inform the customer about the new functionality and thus reduce the number of errors on integration tests.
Expertise in working with third-party systems
To develop billing, we need to be able to keep track of traffic. There are dedicated PCRF systems for this. Calls and SMS are recorded in one database, and traffic in another database; and there is special software that synchronizes both.
But PCRF systems are third-party proprietary software. That is a mystery box: we enter data there, we get something back, but we cannot control what is happening inside. And we can't change anything there.
What we did: we initiated an internal knowledge base on PCRF. Every incident, every setup option, every insight – everything was recorded and shared with the team.
As a result, we have become power users of the PCRF system, we can configure it and understand what it should do. This saves time on simple incidents. With complex cases, of course, we still turn to the developers of the system for help.
More testbeds
Another feature in the testing of mobile operators billing is that use cases can be stretched in time. A use case might take days or even weeks.
We cannot afford to wait days or weeks at the testing stage. In fact, to check such use cases, most often you just fast forward the time in the database.
To fast forward the time, you need to close all the sessions but yours. We get a situation where, let’s say, for 20 testers only two testbeds are available, and everyone needs to fast forward the time. Thus we get a queue. And it means that we might not have enough time to complete the tests by the agreed date of the software shipment.
What we did: we established an individual testbed for each tester.
This allowed us to void the mistakes that happened due to "my turn came too late, I did not have time to do it."
Virtualization
Preparing a testbed is not an easy process, or a quick one either. We had to connect to the operator's network, request accesses to name a few. The complete process could take up to several weeks. Expediting the testbed preparation was yet another an important task towards the zero errors goal.
What we did: we used virtualization.
Copying virtual machines with all the necessary settings, pre-installed software and automating this process helped to prepare the testbeds as quickly as "within one day".
Planning
Errors from integration tests are also the result of miscalculations in the planning of the release. We hitch our wagon to a star, but by the time of the fixed release date haven’t managed it all.
What we did: We introduced intermediate deadlines for each stage of development. "If the end date is known, then every intermediate date is known" – this principle helped us to better control the pace of working towards the release target.
Support and release in parallel
At the beginning of our journey, we faced situations when the "debts" of the previous release conflicted with the following release. After acceptance, bugs arrived, and we all would roll up the sleeves and start fixing them.
The release schedule did not shift. As a result, at a time when it was time to deal with the next release, we could still be working on the previous one.
We managed to change the situation by splitting the team into two groups and assigned one to fix bugs from the acceptance, and the other to work at the new release according to the schedule.
The division was conditional: not necessarily fifty-fifty. We could move people between groups as needed. To an outside observer, it could look as if nothing had changed: during the sprint a team member was engaged both in bugs, and in new features. But in fact, assigning groups was that kind of improvement when we “heave a sigh of relief". The focus of each group and the parallelization of work between groups helped us a lot.
Chronologically, this was one of the first growth areas we defined at our postmortem. And now we’ve come to the second important tool.
Second important tool
The improvement that has been of most use is honest postmortems.
Some call it a retrospective, some call it analysis of the results; in our team the word "postmortem" caught on. All the improvements described in this article were invented at postmortems.
It’s as easy as to get together and honestly discuss how everything went once a release comes out. Sounds simple, but there are pitfalls in making it happen. After a poor release, people in the team are like "no time to chatter, get down to work." Some might come to postmortems and remain silent (and thus, not share potentially valuable information).
Get the full picture
We invite an expanded list of participants. Developers, testers, analysts, managers, executives – everyone who is willing to speak out. Organization-wise, it is not always possible to gather everyone. It's OK, it works that way. The key is that we are not denying participation to colleagues like "we are summing up the results here in our team, you sum up in yours". Work with testbeds, code, processes, interaction – we strive to keep every aspect in sight.
Don't have finger in every pie
So, upon a postmortem, we came up with 30 growth points. Which to start working on? Could we possibly have it all solved by the next time? For us, digging into 2-3 worked best. In this case, we can remain focused, and the efforts of the people in the team are not dispersed. It is better to do less, but iron out the kinks, than a lot but quick-and-dirty.
Don't overcomplicate
There are a lot of approaches to postmortem. Facilitation practices, techniques from design thinking and lateral thinking, Goldratt technique and many others. From our experience, common sense is enough to start. Write down the problems, group them, select several clusters, push aside the rest (see the previous paragraph), discuss, make a plan. When there is a single goal, it is not so difficult to find a common language.
Start doing
Perhaps the main point in this list. No matter how promising and convincing the list of improvements looks like, if no one performs to it, everything is in vain. Agree and commit. Yes, there are other urgent tasks. But we also have a goal, and we want to get closer to it.
Postmortem can be quite a painful process. Talking about failure constructively is not easy. But it’s totally worth it to overcome the pain. I am sure that without a postmortem we would not have come up with all those solutions and wouldn’t have achieved our goal of zero errors in release.
The most important tool
Postmortem allows you to find the means to achieve the goal, but if you delve deeper, you realize it’s effect of a higher-level principle.
The most important tool is team involvement.
Engagement has an instrumental side. For example:
- if we work overtime, the manager is working side by side with the team, fully involved;
- if you encourage the team with some progress tracking, then find visual metrics (for number of errors it’s not rocket science).
And so on.
There is also a difficult to formalize side to involvement – the ability to inspire the team with your belief in success. After all, it didn’t work like we checked the company's values, saw there "stronger together" and exclaimed “Bingo! That’s it! The solution is found!”
We have seen examples of how challenging goals could be achieved through joint efforts. We had people in our team who believed in success and sought to pass that belief on to colleagues. The rest is a matter of technique.
People are the most important.
There was a lot along our way towards the goal of zero bugs in the release. Work on improving documentation, increasing the speed and quality of response to customer questions and such. This time I tried to share only some examples and talk about the basic principles.
My team and I still have a lot to do striving for quality of releases and time-to-market optimization. Make the result with zero errors on integration tests regularly reproducible, automate regression.
How to achieve these goals is yet to be seen. But what we know for sure now: we will definitely have postmortems and implement growth areas based on the outcomes. And we will strive to build on the advantages of the involved teams.
